Workera • Principal Product Designer • 3 months
Turning non-experts into assessment architects
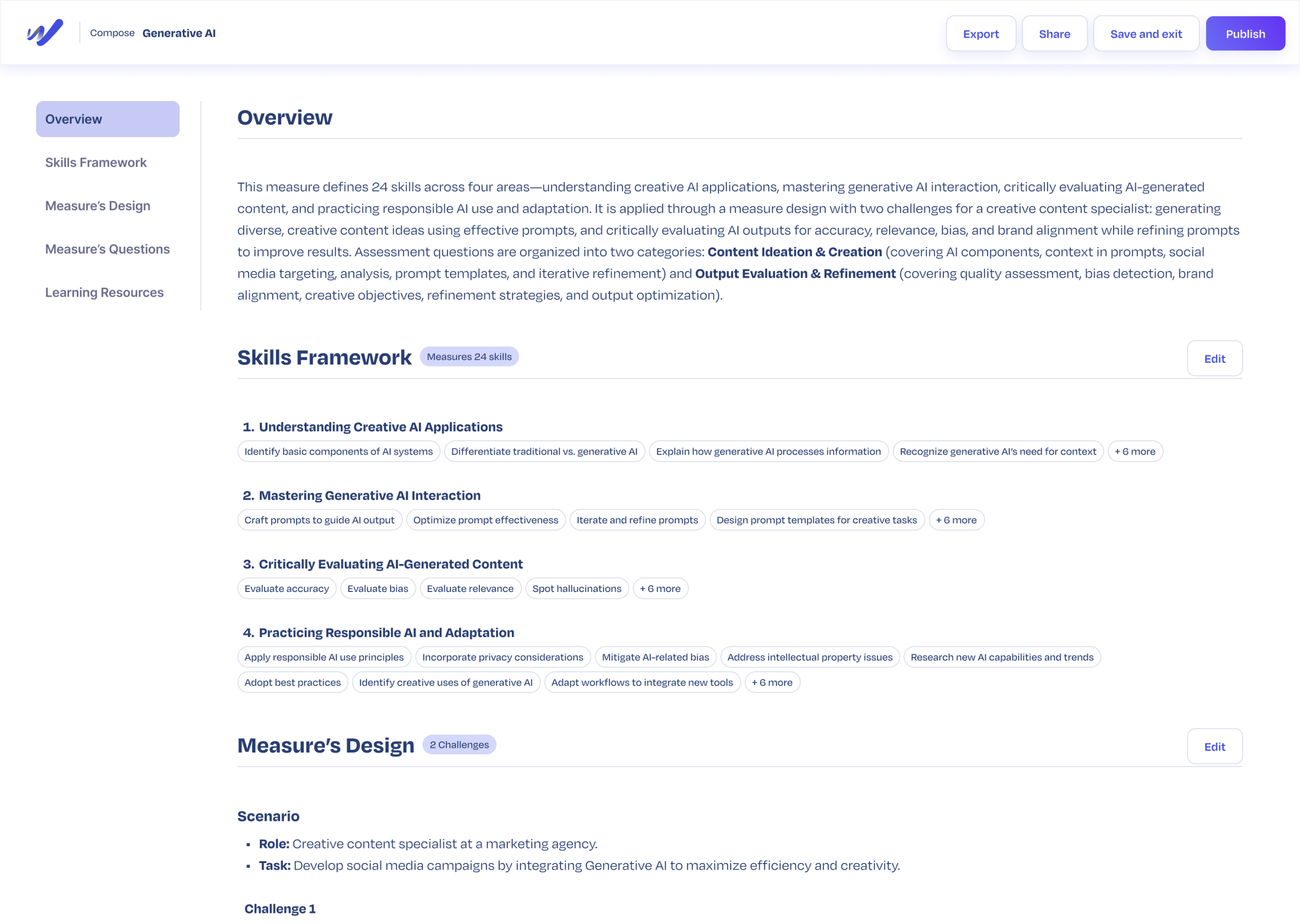
Workera helps organizations evaluate technical skills in AI, data science, and software engineering. Assessments are the foundation of everything we offer, but building one took 4.5 hours of internal manual work every time. Enterprise customers waited weeks to launch programs they’d already paid for. We needed to move from a service model to a platform capability, which meant rethinking who could author an assessment in the first place.
Impact at a glance
- 50+ external assessments generated in the first wave
- +40 NPS admin satisfaction
- Under 30 minutes per assessment, start to publish Internal teams now use
- Compose to expand signature domains faster
The challenge
The people who needed to build assessments, HR leaders, learning managers, transformation officers, had clear goals but none of the underlying structural knowledge. They didn’t think in competency models or item banks. Open-ended tools overwhelmed them. Structured tools confused them, because the language wasn’t theirs.
The real problem wasn’t a skills gap. It was confidence. When admins didn’t understand what they were building, they either gave up or shipped something invalid.
The strategy
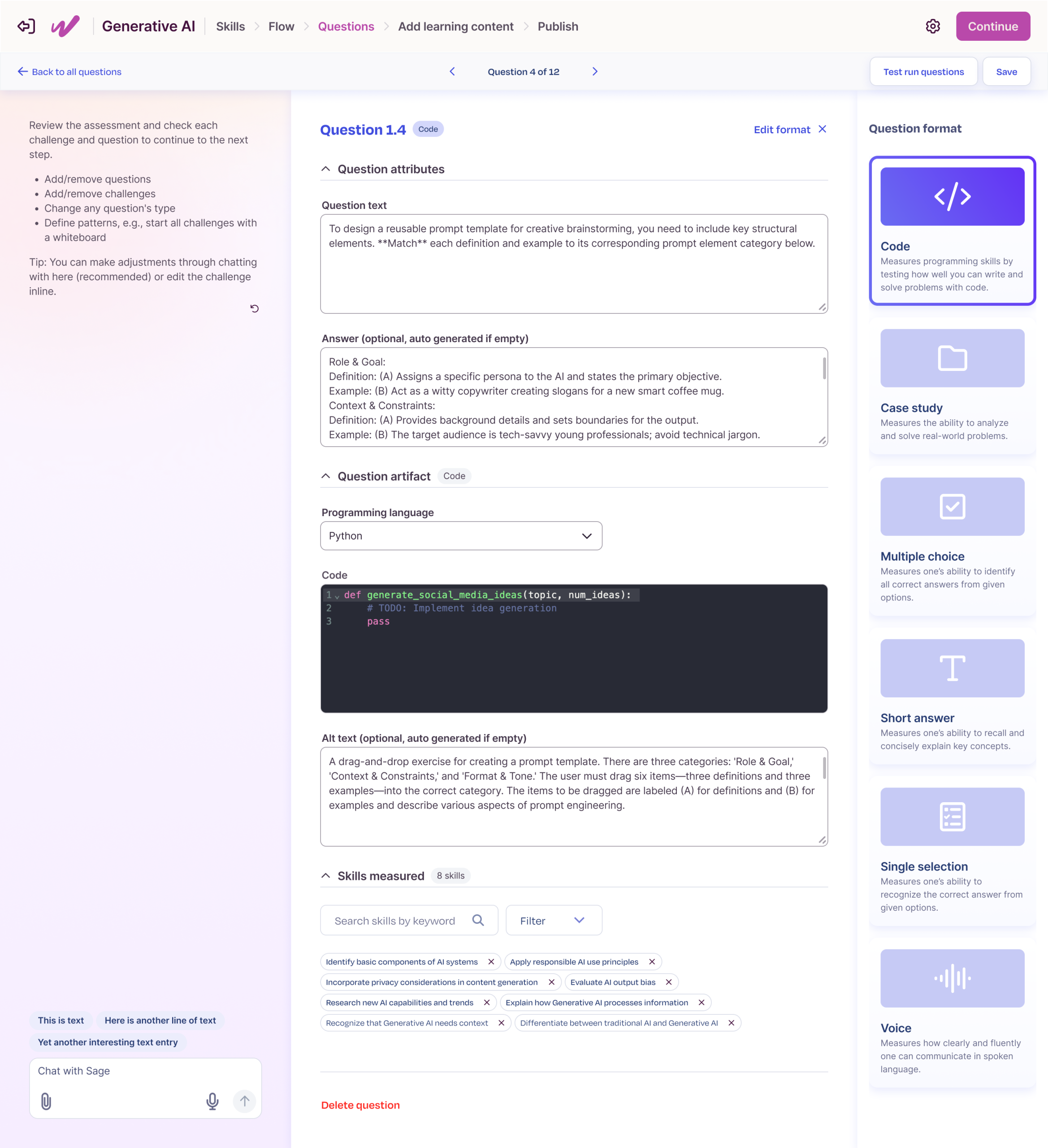
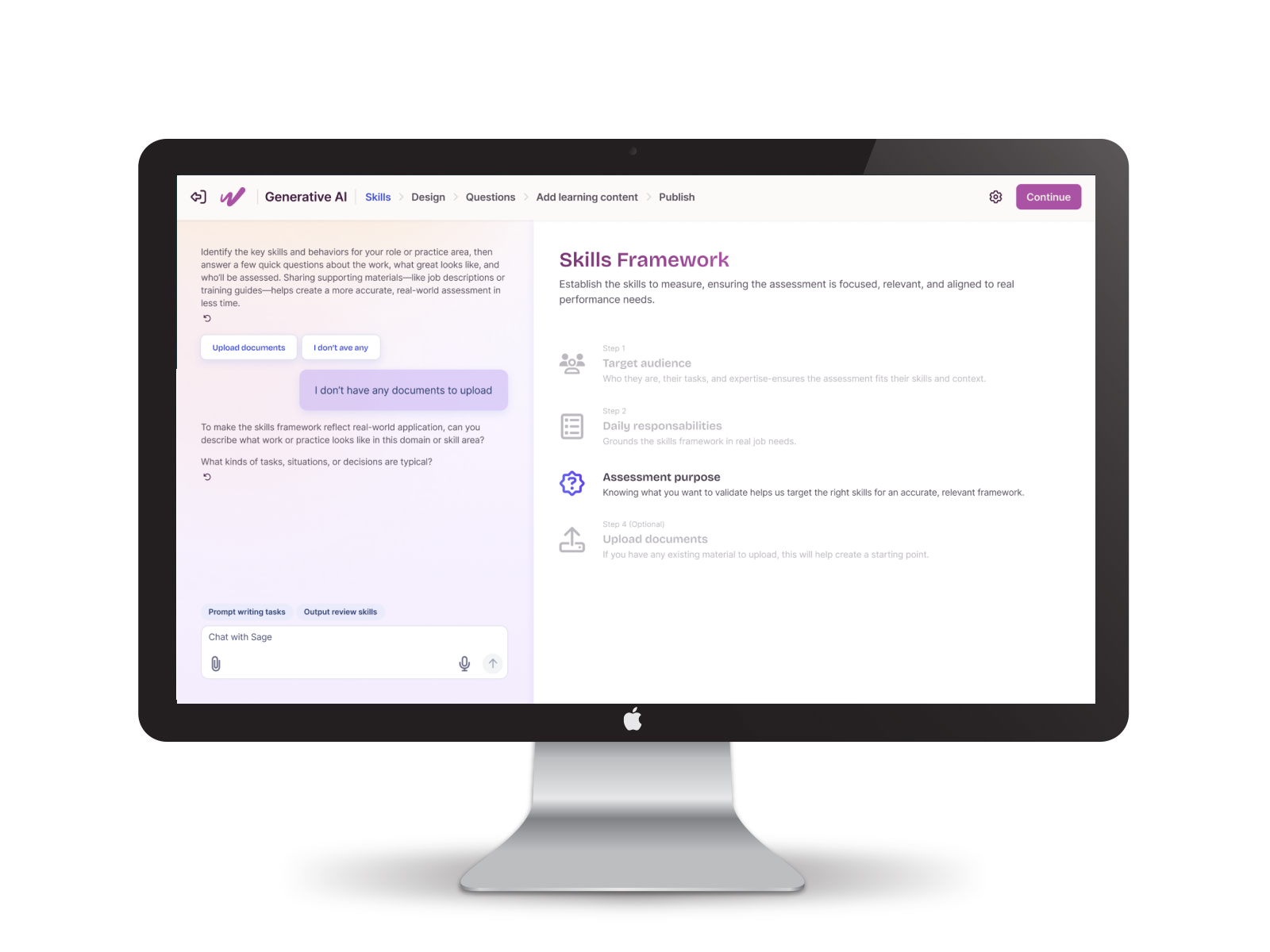
I designed a guided, AI-assisted workflow that split the labor cleanly: admins define what they want to assess, the system handles how it gets structured. The hard part was holding three things in tension at once. It had to teach without being patronizing, stay safe without feeling limiting, and do real work without feeling complex.
I started by interviewing admins about where they got stuck, then sat with internal assessment experts about what they actually needed. The gap was obvious once I saw both sides: admins didn’t know the vocabulary, and experts spent hours translating vague requests into usable briefs.
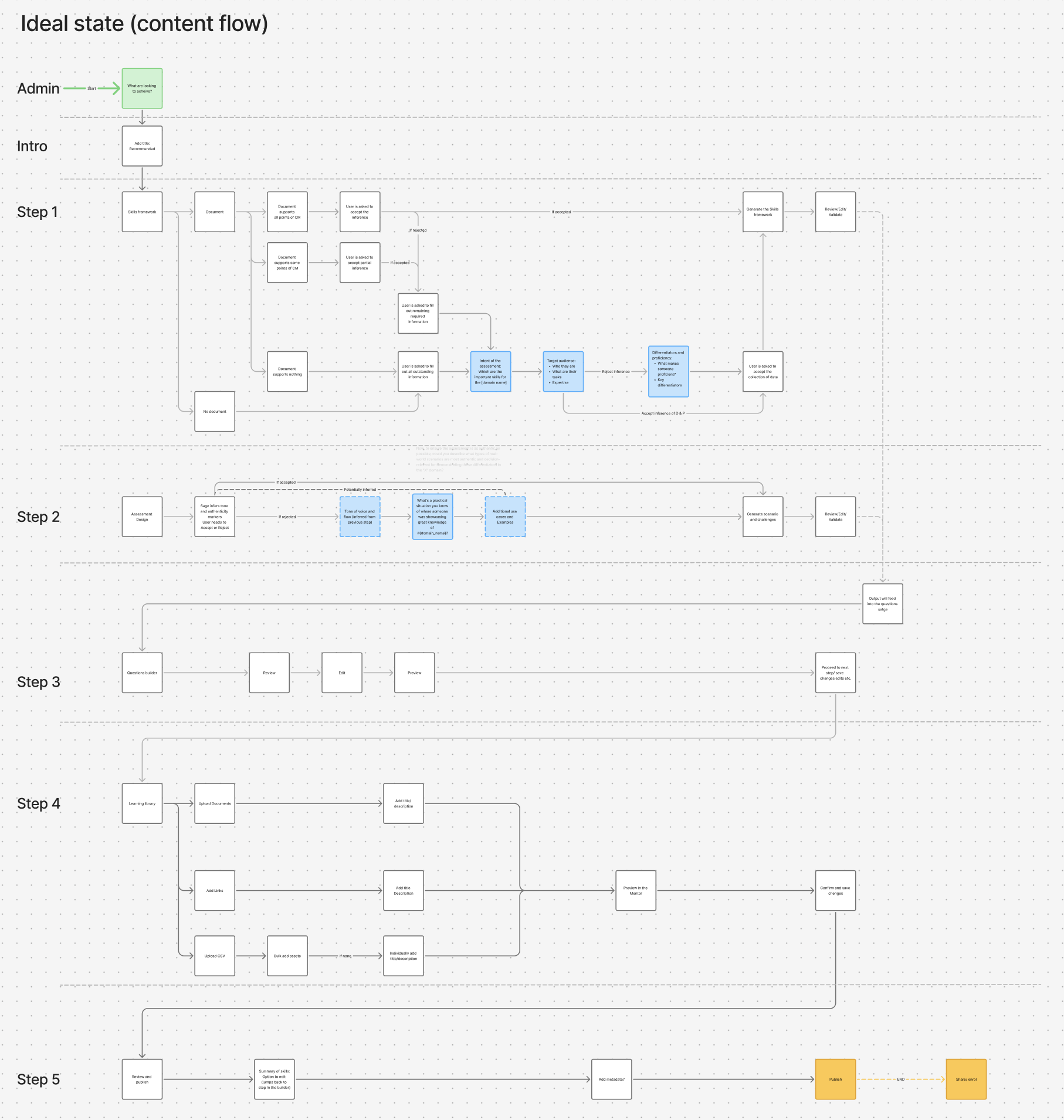
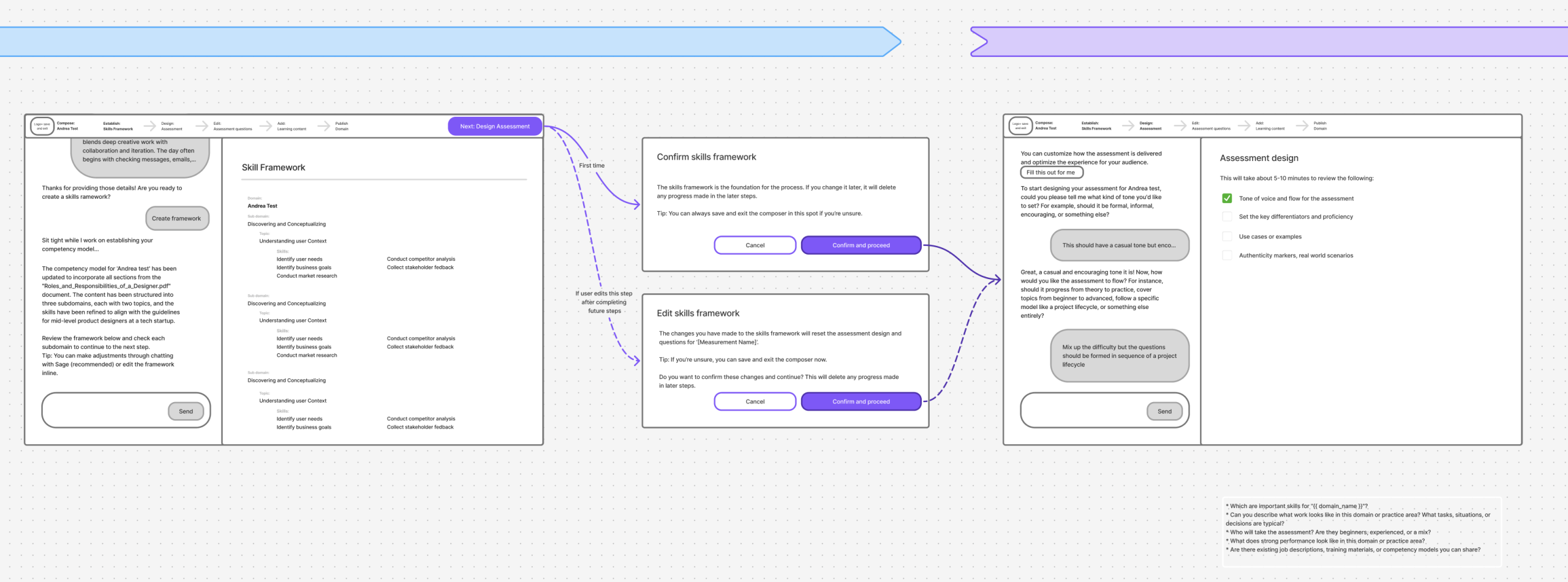
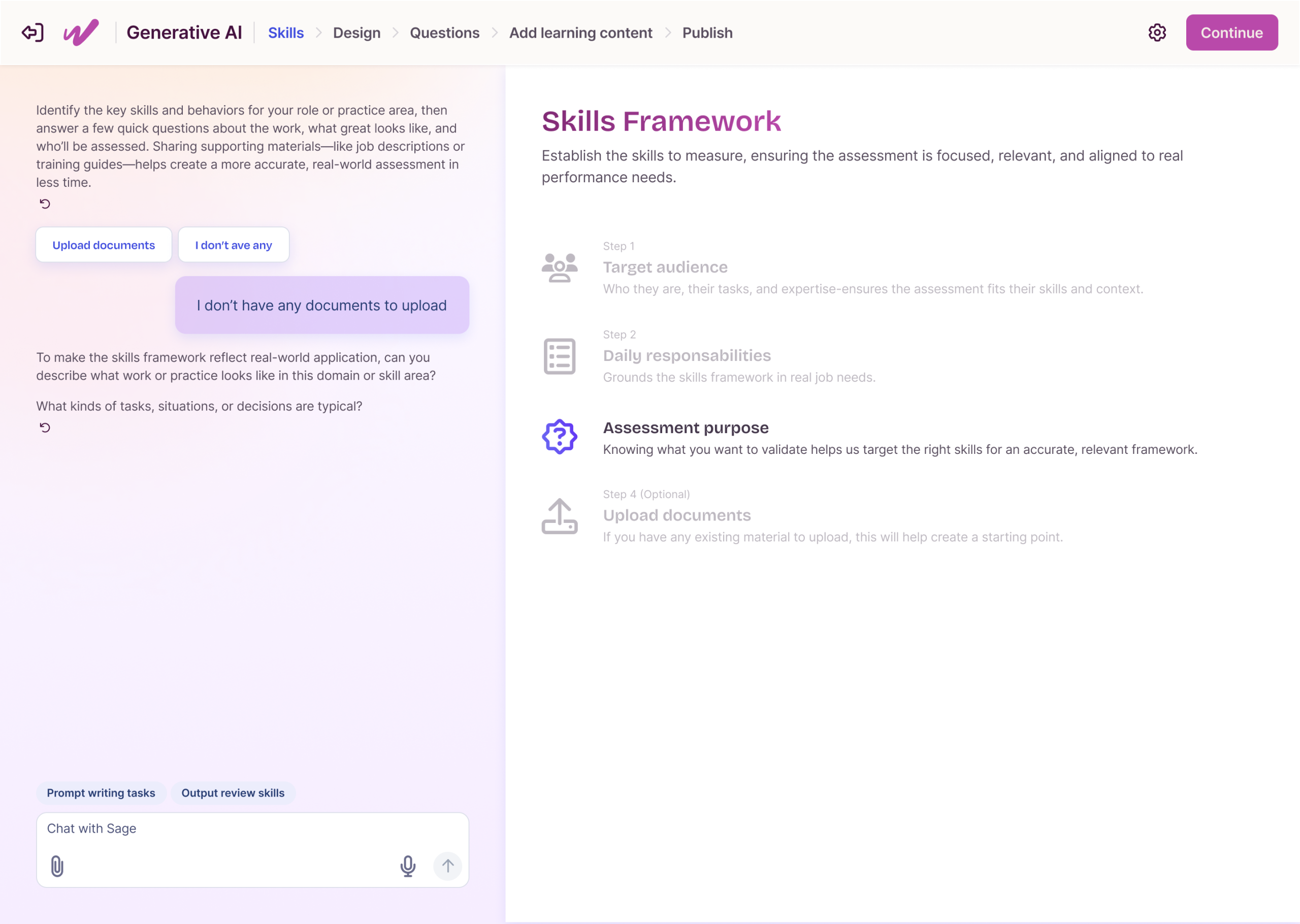
From there, I built a five-step guided flow (define skills, provide context, generate artifacts, review, publish), with our Elo AI agent generating a competency model, outline, and item bank behind the scenes. I added validation checkpoints and reset logic so admins could iterate confidently instead of guessing, and made sure the structured output fed straight into our platform with no manual transcription. I also designed for how the work actually happens: admins could save progress and come back later, because assessment creation is collaborative, not a one-sitting task.
What happened
Admins went from needing 4.5+ hours of internal support to publishing in under 30 minutes on their own. Transcription disappeared entirely, which meant real operational savings that scaled with every new customer. Guardrails nearly eliminated the invalid-attempt cycle that used to plague these projects, and customers launched programs weeks earlier as a result.
“For the first time, I felt like our requirements were actually understood. The assessment reflected what we wanted to teach.” Customer feedback
- Time collapsed Admins completed assessments in under 30 minutes instead of needing 4.5+ hours of internal support. The guided structure meant they always knew what to provide.
- Transcription disappeared Structured data eliminated the need for internal teams to translate admin inputs. That operational savings scaled with every customer.
- Fewer invalid attempts Guardrails and validation prompts nearly eliminated the back-and-forth cycle that plagued these projects.
- Faster onboarding Enterprise customers launched skill programs weeks earlier because they weren’t waiting for internal resources to build custom assessments.
Reflection
The hardest part of this project wasn’t the AI integration, it was the invisible work: progressive disclosure, transparent system behavior, and guardrails specific enough that non-experts could make expert-level decisions without realizing how much was being handled for them.
When admins didn’t understand what they were building, they stalled or shipped something invalid. Fixing that wasn’t about adding more guidance, it was about cutting the points where they had to guess. Knowing which complexity to remove, rather than where to add a feature, is what made the difference here.